

Pokémon or startup?
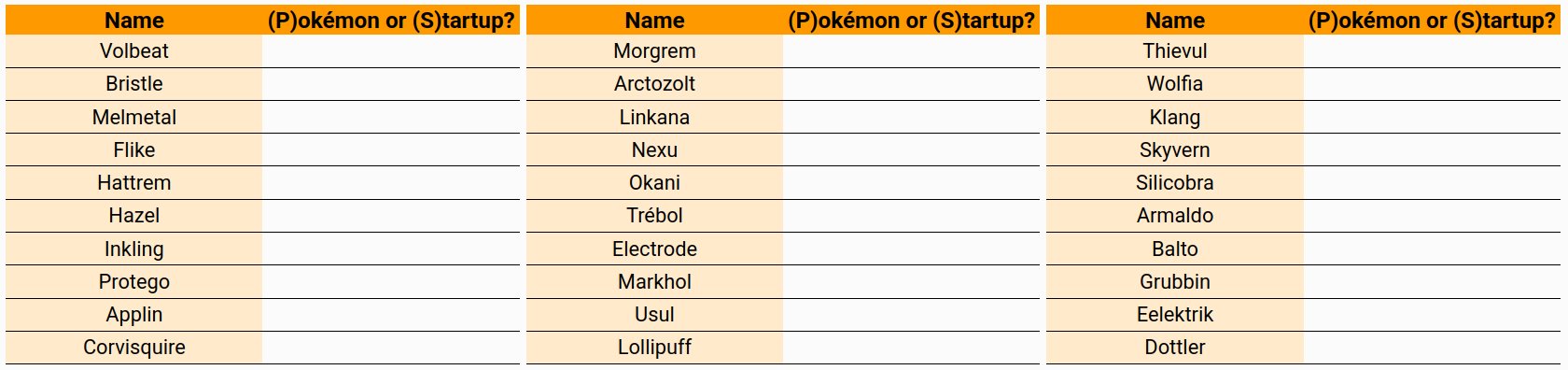
If you want to take the quiz you can find it here, the
rest of this post describes how names were chosen and contains spoilers for the answers.
A while back a friend showed me a quiz posing the age old question: is it a Pokémon, or a pharmaceutical drug? The quiz is surprisingly challenging, possibly because both drug names and Pokémon names attempt to take biology terminology and make it sound cute and marketable. There’s no shortage of quizzes like these either, for example:
You may have also seen this meme:

(I see a total of seven Pokémon.)
While putting together my own quiz it occured to me that instead of spending half an hour manually skimming through hundreds of Pokémon and startup names, I could spend several hours trying to get a computer to do it for me. To do this we would need some kind of statistical model of natural language to quantify how much a name sounds like it would be a Pokémon or startup – farfetch’d right? Conveniently, it just so happens a handful of obscure tech companies and researchers have quietly advanced the state of the art for language modeling over the last few years.
LLMs and confidence
One approach would be to ask an LLM directly how likely it thinks each word is in one category or another. For example:
Prompt: Does “Beartic” sound like a Pokémon or a tech startup? Respond with one of: “Pokémon” or “Tech Startup” and state your confidence as a percentage.
Llama 3.2: Pokémon, 80%
While we could take this at face value, keep in mind the LLM isn’t doing any “introspection” on its own internal workings to come up with “80%”, but rather states a level of confidence that the model would expect to appear in this context. It’s a subtle distinction, but consider what happens if you ask the model a few more times, clearing the context window between attempts:
Llama 3.2: Pokémon (80%)
Llama 3.2: Tech Startup (80%)
Llama 3.2: Tech Startup (70%)
Llama 3.2: Pokémon, 70%
Llama 3.2: Tech Startup. 80%
Despite outputting “Pokémon, 80%” earlier, the odds of it responding with Tech Startup or Pokémon seem closer to 50/50. Also note that regardless of which option it picks, it always claims 70% or 80% confidence in its answer1. If we can’t trust the LLM’s own evaluation of its confidence, how can we measure it? Rather than asking the model about its confidence and relying on its response, we can look directly at the underlying probability distribution that the model samples tokens from. Rerunning with logprobs enabled, the top 5 options for the first token are:
| First Token | logprob | \(\textbf{e}^\textbf{logprob}\) |
|---|---|---|
Tech |
-0.45017755 | 63.75% |
Pok |
-1.1627344 | 31.26% |
Be |
-4.1083674 | 1.64% |
Startup |
-4.659017 | 0.95% |
Start |
-4.826072 | 0.80% |
Based on the first token, it appears the model has a 63.75% chance of responding with “Tech Startup”, and a 31.26% chance of responding with “Pokémon2. The remaining 5% of the time the model ignores our instruction to respond only with “Tech Startup” or “Pokémon”, which for the sake of simplicity we will ignore. Excluding answers that don’t fit the expected format and normalizing, we find that the model answers “Tech Startup” 67.11% of the time, and “Pokémon” 32.89% of the time.
Results




Applin, Silicobra, Klang and Grubbin.
Now that we can measure how likely an LLM is to categorize a name as a Pokémon or a startup, we can go through lists of both categories and search for good candidates for the quiz. In order to make the quiz as difficult as possible, we want to find Pokémon that sound like they could be a startup, and startups that sound like they could be a Pokémon. For the list of Pokémon, I included everything up to Sword and Shield (2019), since the next major releases Scarlet and Violet (2022) came out fairly close to Llama 3’s knowledge cutoff date. Our top 15 are:
| Name | Pokémon | Tech Startup |
|---|---|---|
| Applin | 12.69% | 87.31% |
| Electrode | 16.04% | 83.96% |
| Melmetal | 23.45% | 76.55% |
| Dottler | 26.49% | 73.51% |
| Silicobra | 26.75% | 73.25% |
| Corvisquire | 26.82% | 73.18% |
| Polteageist | 27.13% | 72.87% |
| Eelektrik | 27.23% | 72.77% |
| Arctozolt | 28.63% | 71.37% |
| Morgrem | 29.85% | 70.15% |
| Hattrem | 30.10% | 69.90% |
| Volbeat | 30.11% | 69.89% |
| Thievul | 30.41% | 69.59% |
| Armaldo | 30.77% | 69.23% |
| Klang | 31.48% | 68.52% |
This list mostly sounds plausible to me other than Polteageist3, Morgrem and Hattrem. Looking closely, those three and six others (Applin, Dottler, Silicobra, Corvisquire, Arctozolt, and Thievul) all come from the most recent games included in the dataset, Sword and Shield. I suspect since newer Pokémon appear less frequently in Llama 3’s training data, they’re more likely to be confused for a startup than older, well-known Pokémon like Pikachu or Charizard. Some highlights for me are:
- Silicobra, which is so straightforward (“silicon” + an animal) it almost sounds like it was made up just for the quiz.
- Applin, which I initially thought was ranked highly because of Apple before realizing it could also be a play on software “apps”.
- Klang, which is robotic sounding but also remniscent of abbreviations for “programming language” like in Clang, Erlang and Golang.
- Honorable mention to Grubbin in 16th place, which sounds like it could be yet another food delivery or meal kit startup.
Switching our attention to startups that sound like Pokémon, I took startup names from this dataset of Y Combinator backed companies. Our top 15 are:
| Name | Pokémon | Tech Startup |
|---|---|---|
| Ditto | 85.89% | 14.11% |
| Wren | 73.82% | 26.18% |
| Koala | 72.13% | 27.87% |
| Protego | 70.91% | 29.09% |
| Nexu | 70.30% | 29.70% |
| Manatee | 70.24% | 29.76% |
| Hedgehog | 69.57% | 30.43% |
| Hedgehog | 69.57% | 30.43% |
| Remora | 68.75% | 31.25% |
| Wasp | 68.52% | 31.48% |
| Okani | 68.51% | 31.49% |
| Platypus | 66.89% | 33.11% |
| Lollipuff | 65.26% | 34.74% |
| Corgi | 65.14% | 34.86% |
| Skyvern | 62.58% | 37.42% |
The number one spot goes to Ditto, a startup making devtools for localization and legal copy. This makes sense, since it’s also literally the name of a Pokémon. Most of the other spots are filled by the names of real life animals, including two different startups named Hedgehog: one that tried to make “a crypto robo-adviser” and one working on “robotic mushroom farms”. Cleaning up the dataset to remove literal animals and Pokémon, we get:
| Name | Pokémon | Tech Startup |
|---|---|---|
| Protego | 70.91% | 29.09% |
| Nexu | 70.30% | 29.70% |
| Okani | 68.51% | 31.49% |
| Lollipuff | 65.26% | 34.74% |
| Skyvern | 62.58% | 37.42% |
| Inkling | 62.27% | 37.73% |
| Linkana | 62.12% | 37.88% |
| Bristle | 62.11% | 37.89% |
| Trébol | 61.01% | 38.99% |
| Usul | 58.58% | 41.42% |
| Flike | 58.29% | 41.71% |
| Markhor | 58.25% | 41.75% |
| Balto | 56.74% | 43.26% |
| Hazel | 55.91% | 44.09% |
| Wolfia | 55.89% | 44.11% |
Some highlights for me:
- Lollipuff, a luxury goods auction service, which sounds like it would fit right in with Pokémon like Igglybuff, Jigglypuff, Wigglytuff, and Jumpluff.
- Skyvern, an “open source AI agent” not to be confused with Noivern and other Flying/Dragon type Pokémon.
- Inkling, a “collective intelligence solutions” service which sounds like it could be a squid or an octopus Pokémon, and shares a name with the mascots of a different Nintendo franchise.
Final thoughts
I came up with this idea on a whim and it worked out surprisingly well. If you want to play around with your own ideas, everything was done with a llama.cpp and a simple Python script uploaded here. Anyway, thanks for reading!
-
My best guess for why the confidence is in the 70% to 80% range regardless of the choice is people are more likely to publicly share opinions or guesses they’re confident about, leading to selection bias in the training data. I’m about 70% confident in this theory. ↩
-
These percentages assume that the LLM’s temperature parameter is set to 1. If it’s less than 1, it would favor “Tech Startup” even more. ↩
-
I ended up removing Polteageist and adding Grubbin (16th place) in the quiz. I suspect it was labeled confidently as a startup not because it sounds like a startup, but because “poltergeist possessing a pot of tea” sounds ridiculous even for a Pokémon. ↩